Apple Intelligenceの話もあり、更なる盛り上がりを見せている生成AI。ChatGPTやGeminiと違いローカル動作がベースということで、プライバシーの面から安心な生成AIを求める層にはかなり刺さる新機能となった。
しかしオフラインで動作する生成AIについては、これまでもローカルLLM・オンデバイスAIと呼ばれ各所で研究開発が盛んに行われていた。既に個人規模で手軽に扱えるレベルにまで進歩しており、それなりのハードウェアさえあれば簡単にテストが可能である。
そしてAppleシリコンを搭載したMacは、あらゆる面からローカルLLMの実行に最適である。今回はM1チップのMacminiを使って、自由に使える環境を組み上げた。
MacでローカルLLMを稼働させるメリット
生成AIはNPU>GPU>CPUの順で効率的に動かせるらしいけど、MacのSoCであるAppleシリコンは低廉でありながらこの3種全てが高性能。自由に割り振れるユニファイドメモリの恩恵でGPUにも積極的にメモリを使えるため、SoCの構成から既に他のデバイスより圧倒的に優位であり隙がない。
Appleシリコンのグレードを上げればそれだけ大きなモデルを快適に動かせるようになり、最低ランクである8GBメモリのM1チップですら実用的なレベルのモデルを動作させられる性能がある。
MacStudioやMacProのようなUltraシリーズのチップであれば、ChatGPT3.5にも劣らない性能を発揮出来るモデルを動作させられる。
このような特性から「MacでローカルLLMを動かす」という新ジャンルが確立されており、既に多くの先駆者達があらゆるモデルを動作検証・改良している。AppleシリコンのMac自体が低廉なハードウェアであることから、参入ハードルはかなり低いと言える。
ローカルLLMはChatGPTやGeminiを始めとした大手の生成AIと異なり、自分で管理するデバイスの上でオフライン動作するため外部との通信が発生しない。入力したデータを学習に使用される恐れもなく、プライバシーの面で遥かに優れていると言える。
その特性上個人情報や企業データを積極的に使いやすく、個人用途から企業規模まで広く対応可能。
基本的にはデバイス上で動作させることになるが、ブラウザから使えるUIを用意した上で自前でサーバーを立ち上げることも可能(WebUI)。自前のサーバーとして完全に管理可能であり、プライベートなデータを含む入力をしながら複数デバイスで使えるようになるため非常に役立つ。自宅サーバーで稼働させつつ外出先からアクセスすることも難しくない。
モデルデータはオープンソースのものを流用し、時にはそれをベースにカスタマイズされたモデルを用いることもある。
今回は最も有名なMeta製の最新型「Llama 3」に日本語を学習させたモデルを用いてサーバーを構築し、どこからでもアクセス出来る状態を目指す。
実行中はメモリが5GBほど持っていかれるが、効率的なメモリ管理が可能且つ軽量なため8GBメモリのデバイスでも十分に実行可能なのはmacOSの強み。
構築手順
サクサクと上から。
モデル実行に必要なファイルを揃える
Ollama
公式サイトよりLLMの実行環境であるOllamaをダウンロード。
Mac版をダウンロードしたら、アプリケーションフォルダに配置して実行。ボタンをワンクリックすることで、コマンドラインが使用可能になる。

言語モデルのダウンロード
これがLLMの本体となる。→リンク
Ollamaには言語モデルを拾ってくるストア的な機能もあるが、Llama3公開直後だからか日本語モデルはなかったので野良のモデルを使用。Llama3をベースとし、日本語利用に特化させた軽量モデル。
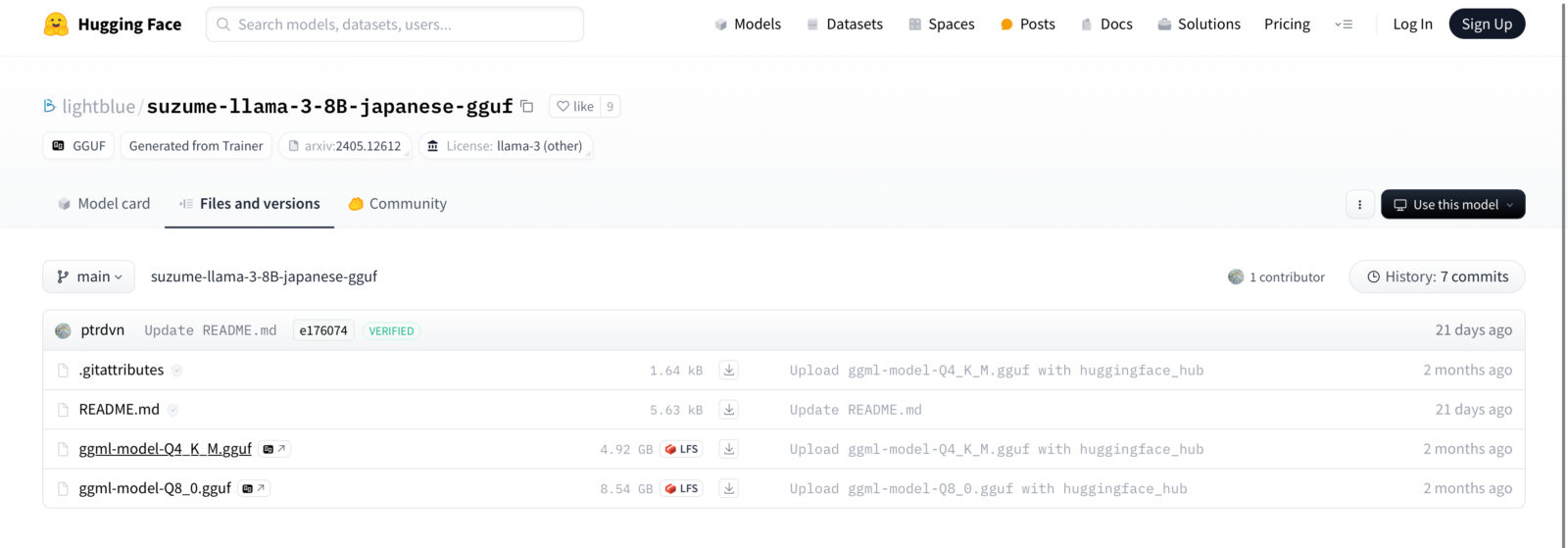
メニューからFiles and versionsにアクセス、ggufファイルをダウンロードする。
2種類あるが今回は5GB弱のQ4_K_Mを選択。言語モデル本体の容量が大きいほど使う際に処理能力・メモリ容量を必要とし、M1チップ/メモリ8GBだとこちらが限界。
保存する先として専用フォルダを割り当てておくと後が楽。
Modelfile(プロファイル)の作成
野良のモデルを使う場合、Modelfileと呼ばれるプロファイルのようなものを作成する必要がある。
これはどのモデルをどのように使うか記したもので、同じモデルでも用途別に作って使い分けることが出来たりする。とはいえ細かい部分は知識がなく弄れないのでほぼ流用丸コピ。
テキストエディットで標準テキストを作成し、以下の内容をコピペ。
FROM ./ggml-model-Q4_K_M.gguf
TEMPLATE "{{ if .System }}<|start_header_id|>system<|end_header_id|>
{{ .System }}<|eot_id|>{{ end }}{{ if .Prompt }}<|start_header_id|>user<|end_header_id|>
{{ .Prompt }}<|eot_id|>{{ end }}<|start_header_id|>assistant<|end_header_id|>
{{ .Response }}<|eot_id|>"
SYSTEM You are a helpful, smart, kind, and efficient Japanese AI assistant. You always fulfill the user's requests to the best of your ability in Japanese. This is first priority that you must respond answers in Japanese.
PARAMETER temperature 0.3
PARAMETER top_k 10
PARAMETER top_p 0.5
PARAMETER stop <|start_header_id|>
PARAMETER stop <|end_header_id|>
PARAMETER stop <|eot_id|>
PARAMETER stop <|reserved_special_token|>
PARAMETER stop <|im_end|>
PARAMETER stop <|im_start|>
最初のFROMはggufファイルの場所を指している。
同フォルダに配置する場合は「./」で親フォルダを指定できるので、画像のように「./モデル名.gguf」で事足りる。
終わったらモデルと同じ場所に保存。
拡張子をしっかり.modelfileにしておくことを忘れずに。
Ollamaに読み込ませる
ターミナルを開き、以下のコマンドでModelfileとモデルを読み込ませられる。
ollama create プロファイル名 -f モデルファイルのパスプロファイル名は自由に。あとで実行時に使う。(わたしはlightblue-llama3)
モデルファイルはフルパスで記載。Macの場合はFinderでファイルをコピーしておけばフルパスを貼り付けられる。
WebUIを立ち上げる
サーバーとして立ち上げる場合、事前にDDNSアドレスの確保を行なった上でVPN環境を構築しておくことが必要。
DDNSアドレス+ポート開放でもアクセスはできるものの、わたしの環境ではサインインボタンが押せなかった。原因不明(もしかしてセキュリティ上の理由?)
サーバーを立ち上げずに環境構築したデバイスのみで実行する予定なら、DDNSアドレスとポート開放/VPNのいずれも不要。ただその場合でもより優れたUIで実行できるため、WebUIは立ち上げておくことを勧める。
WebUIはVPN環境構築でも使ったDockerで構築する。
Docker Desktopのダウンロード
公式サイトよりMac版をダウンロード。
サーバー起動
以下のコマンドで全ての設定が完了する。
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v ollama-webui:/app/backend/data --name ollama-webui --restart always ghcr.io/ollama-webui/ollama-webui:main使用方法
DockerでWebUI環境を構築していない場合、以下のコマンドで扱える。
ollama run プロファイル名
ターミナル上で呼び出すことになり、会話も全てターミナル上で行う。
この状態でも便利だが、改行やコピペが微妙にしづらい。
Web UIを使う場合
DockerでWebUIのコンテナを起動し、localhostの3000番ポートにアクセス。(http://localhost:3000)
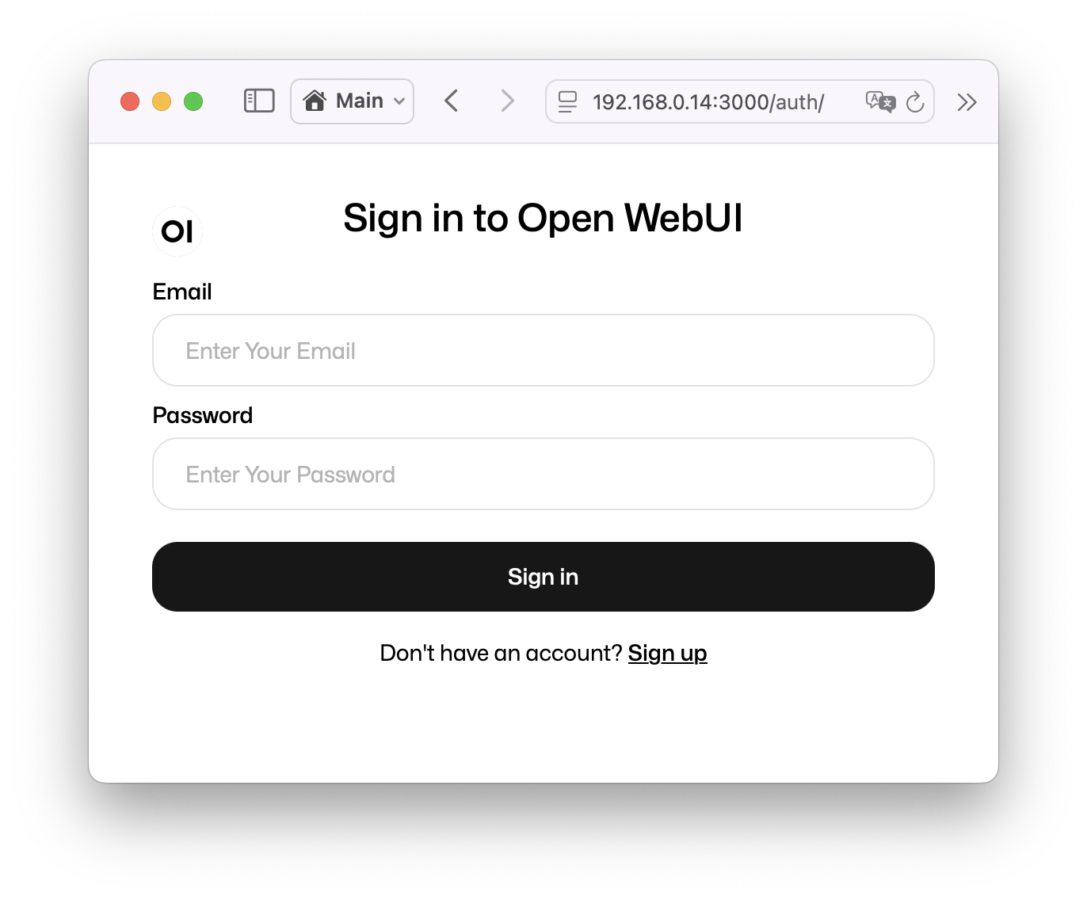
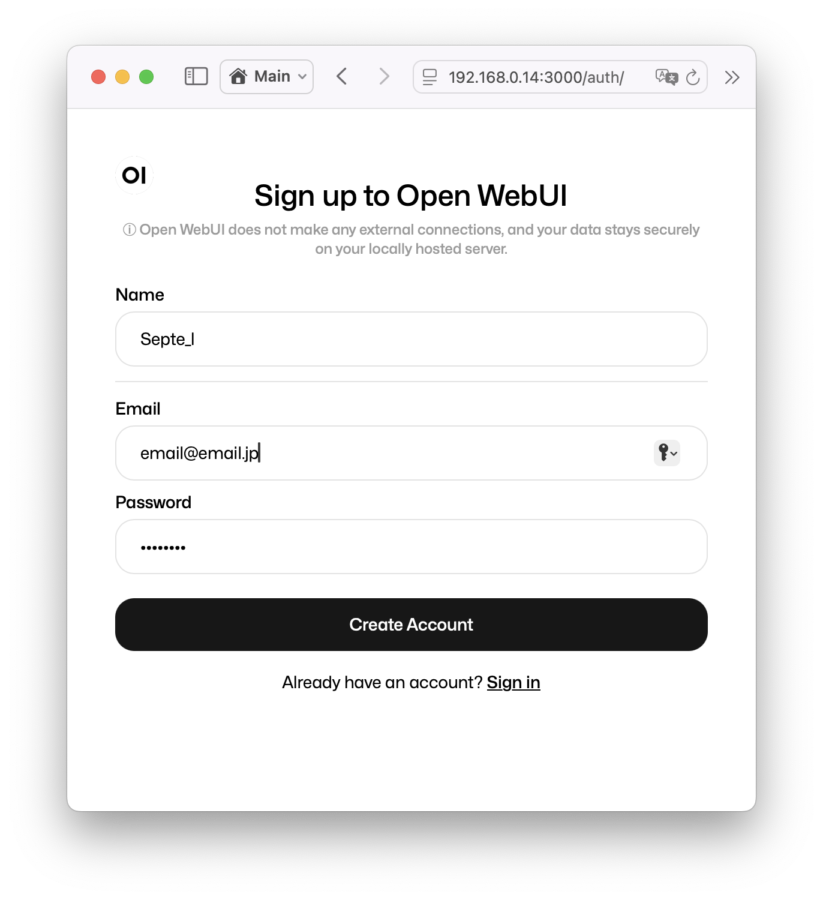
メアドパスとユーザー名を指定してサインイン。これは今後のユーザー識別に使われる。
これでChatGPT的なUIが使えるようになる。

遠隔で扱いたい場合はVPNに接続し、サーバー機のローカルIP宛ににアクセスすればOK。
(http://192.168.XXX.XXX:3000)
外出先で好きなデバイスから、自宅のサーバーマシンの演算能力を使って生成処理が行える。
所感
生成AIは盛り上がりを見せると同時に、使い方の模索も盛んに行われている新ジャンル。
ただ文章や画像を生成出来るだけでは価値を見出しづらく、生成物をどのように扱うかが本題。自前でサーバーを立てておけば生成AIによる分岐処理を含んだオートメーションが個人規模で組めるので、ローカルで動かせる生成AIが輝く。
同じサーバーマシンにn8nやDifyを組み込めば、個人規模で高度なAI利用が可能。iPhone等からショートカットAppでSSHコマンド/HTTPリクエストを送るかiCloudDriveへの同期+Automatorのフォルダアクションをトリガーにして、処理結果はiCloudDriveに出力するといったことも可能だろう。
わたしもこれを目指してもう少し模索を続けてみる予定。
Appleシリコンを搭載したMacminiはAIサーバーとして非常に優れており、小型省電力ながら生成AIを組み込んだ自動化処理までこなせてしまう。
より大きなモデルを動かすにはハイエンドのSoCを搭載したMacStudioが必要になるが、Llama3の8B程度であればM1チップでも十分に動かせる。
Apple IntelligenceはこうしたオンデバイスAIを活用した自動化処理を多数組み込んでくれているが、Ollamaを始めとしたローカルLLMを導入すれば自分好みにカスタマイズすることも出来る。
Apple Intelligenceに出来ないことを模索するもよし、Apple Intelligenceが日本語対応する来年までの繋ぎにしてもよし。夢が広がる新技術は、使い手の想像力次第でどこまででも活用出来る可能性を秘めている。
参考サイト:
【Ollama】ローカル Llama3 日本語環境を整える【8B】
https://note.com/catap_art3d/n/n06d6a4f32e06
ローカルでLLMの推論を実行するのにOllamaがかわいい
https://zenn.dev/seya/articles/03399b9e3d465e